
Матрица путаницы — это таблица, которая часто используется для описания производительности модели классификации (или «классификатора») на наборе тестовых данных, для которых известны истинные значения. Сама матрица путаницы относительно проста для понимания, но связанная с ней терминология может сбивать с толку.
Цель прикладного машинного обучения в промышленности — повысить ценность бизнеса. Поэтому возможность оценить производительность ваших алгоритмов машинного обучения чрезвычайно важна для понимания вашей модели.
Независимо от того, на какой участок сетки вы попали на рисунке ниже, соседняя с ним сетка будет выделена другим цветом. При этом учитываются различные варианты матрицы путаницы, которые вы можете увидеть, если просто повернете сетку.
Что такое матрица путаницы?
Цель прикладного машинного обучения в промышленности — повысить ценность бизнеса. Поэтому возможность оценить производительность ваших алгоритмов машинного обучения чрезвычайно важна для понимания вашей модели.
В настройках двоичной классификации, где отрицательный класс равен 0, а положительный класс равен 1, матрица путаницы создается с помощью таблицы сетки 2x2, где строки представляют собой фактические выходные данные, а столбцы — это прогнозируемые значения из модели.
Примечание. Многие источники по-разному структурируют матрицу путаницы, например, строки могут быть предсказанными значениями, а столбцы — фактическими значениями. Если вы используете фреймворк (например, Sci-kit learning), важно прочитать документацию по матрице путаницы, чтобы узнать, в каком формате находится матрица путаницы.
Вы только что начали машинное обучение и завершили контролируемую линейную регрессию. Теперь вы можете строить модели с хорошим показателем точности. Теперь вы переходите к модели классификации. Вы обучаете модель и тестируете ее на проверочных (тестовых) данных, и вуаля, вы получаете колоссальный показатель точности 91%. Но является ли точность правильным методом оценки для вашей модели? Матрица путаницы ответит на этот вопрос.
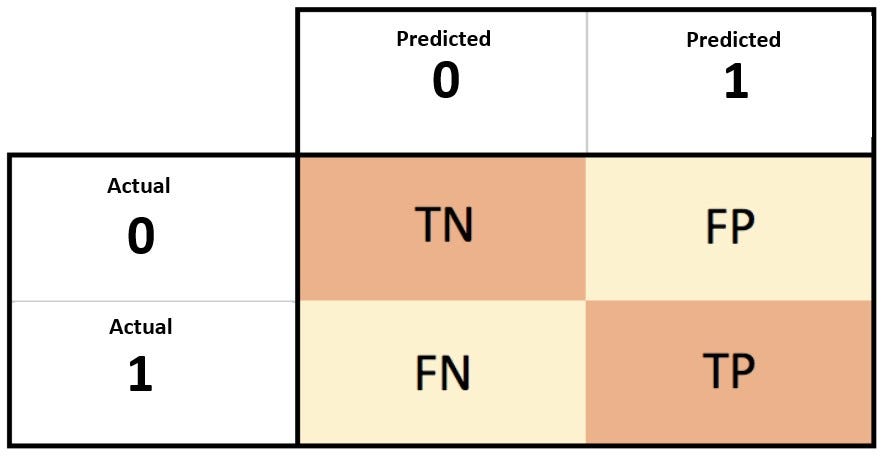
Истинные положительные результаты. Модель предсказывала положительный результат, и метка действительно была положительной.
Истинно отрицательные результаты.Модель предсказывала отрицательный результат, и метка была фактически отрицательной.
Ложные срабатывания.Модель предсказывала положительный результат, а метка была на самом деле отрицательной. Мне нравится думать об этом как о ложно положительном результате.
Ложноотрицательные результаты.Модель предсказывала отрицательное значение, а метка была на самом деле положительной. Мне нравится думать об этом как о ложно отрицательном результате.
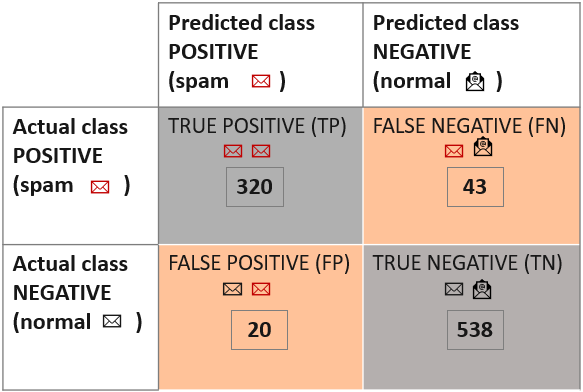
Давайте разберемся с четырьмя частями на примере спам-фильтра. Есть электронные письма, которые являются спамом и не являются спамом. Наш спам-фильтр предскажет это.
1) Истинно отрицательные результаты (TN): исходно не спам, предсказано как не спам.
2) Истинно положительные результаты (TP): исходно спам, предсказано как спам.
3) Ложноотрицательный (FN): Первоначально спам, предсказанный как не спам.
4) Ложноположительный результат (FP): Первоначально не спам, предсказанный как спам.
Мы ясно видим, что TN и TP являются правильными предсказаниями нашей модели, и что точность можно рассчитать по формуле: (TN+TP)/(всего предсказаний). Но компании редко принимают решения исключительно на основе показателя точности. Существует множество значений, полученных из матрицы путаницы, таких как чувствительность, специфичность, полнота, точность и т. д., которые предпочтительны в зависимости от решаемой бизнес-задачи.
Пример использования — @Kurtis Pykeshttps://kurtispykes.medium.com/ (энтузиаст искусственного интеллекта и машинного обучения)
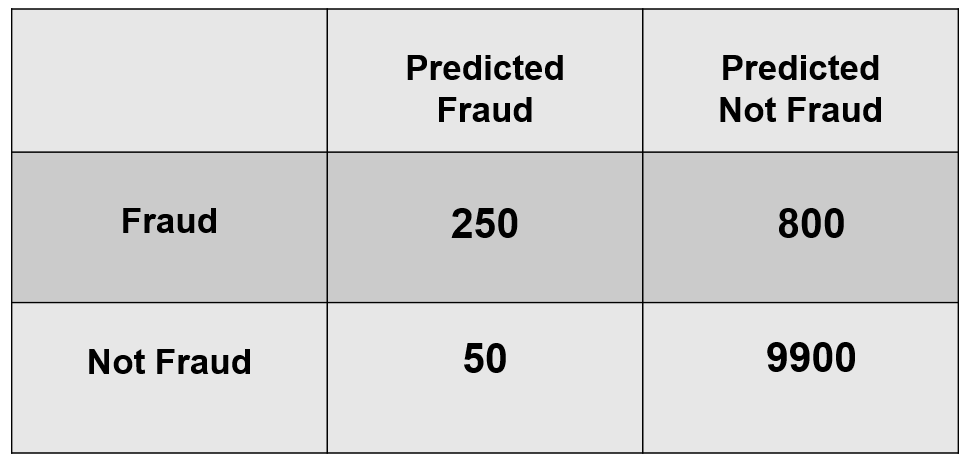
Перед ним стоит задача создать классификатор, который прогнозирует мошеннические или немошеннические транзакции для различных транзакций. Данные были переданы нам крупным банком в Великобритании с очень строгой защитой — личные данные всех клиентов были зашифрованы из соображений конфиденциальности — поэтому мошеннические транзакции случаются не так уж часто. На самом деле данные, которые они нам предоставили, содержали 10 000 отрицательных случаев (не мошенничество) и 1000 случаев (мошенничество). На рисунке ниже показаны результаты нашего классификатора.
Точность
Точность относится к близости измеренного значения к стандартному или известному значению. После того, как мы создали классификатор и использовали его для прогнозирования, мы быстро подняли нашу матрицу путаницы, чтобы определить, насколько точной была наша модель, и мы были поражены, увидев, что наша модель имеет точность 92%. Когда мы начали мечтать о нашем бонусе, который должен был быть получен от этого, что-то дернуло нас за науку о данных и посоветовало нам больше изучать прогнозы наших моделей, потому что мы не знаем, почему наша модель настолько точна. и потому что точность может ввести в заблуждение, когда наша целевая переменная, в данном случае мошенничество или отсутствие мошенничества, несбалансирована. Мы еще раз просмотрели матрицу неточностей (см. рисунок), чтобы вывести еще несколько показателей, объясняющих, почему наша модель так точна.


Точность и полнота
Точность (также называемая положительным прогностическим значением) говорит нам, что из меток, которые наш классификатор пометил положительными, сумма, которая на самом деле является положительной.

Примечание. Точность и полнота основаны на понимании и оценке положительного ярлыка (релевантности).
Мы вычисляем формулы, которые мы только что выучили, для точности и припоминания:
Точность = 83 %
Да!! Это фантастика, это означает, что 83% ярлыков, которые мы пометили как положительные, на самом деле положительные. Это феноменально… или нет? Проверим отзыв.
Вспомнить = 24%
Whooppsie daisy… Это говорит нам о том, что количество положительных меток, которые наш классификатор правильно идентифицирует как таковые. Другими словами, мошенничество остается незамеченным в 76% случаев! Не нужно быть доктором философии, чтобы знать, что это совсем нехорошо.
Для этой проблемы мы хотели бы оптимизировать отзыв, а это означает, что мы хотели бы уменьшить количество ложноотрицательных результатов (ложно классифицируемых как отрицательные, когда фактическая метка положительна), предсказывая положительные результаты в большем количестве случаев. Однако бывают случаи, когда вы можете захотеть оптимизировать точность, например, в классификаторе спама, мы бы не хотели, чтобы важные электронные письма классифицировались как спам и отправлялись в нашу нежелательную почту. В случае нашего классификатора мошенничества мы хотим оптимизировать отзыв, и для этого мы должны уменьшить порог классификатора для того, что он классифицирует как положительный класс. Обратите внимание, что, поскольку наш классификатор теперь предсказывает больше положительных результатов, он снижает (нашу когда-то отличную) точность на 83%, потому что теперь есть более высокая вероятность того, что наша модель будет предсказывать ложные положительные результаты, вызывающие больше ложных тревог, но мы не возражаем против того, что в этот экземпляр.
Точность и отношения любви и ненависти
Очень редко точность и полнота обсуждаются изолированно, и, как мы обнаружили выше, между ними часто существует обратная связь — увеличение одного показателя снижает другой. Когда нам нужно найти баланс между точностью и отзывом, более известной метрикой является оценка F1 (также известная как показатель F). F1-оценка — это мера точности, которая учитывает точность и полноту (приведенная ниже формула покажет вам, как она это делает).
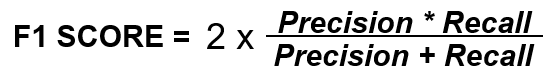
Вывод:
Я надеюсь, что эта статья показалась вам интересной, и теперь вы лучше понимаете, как можно использовать матрицы путаницы в реальных бизнес-сценариях. Жду ваших отзывов в комментариях.